資料自動化(Data Automation)服務使用說明
概述
本專案流程提供自動化資料生成與資料品質評估服務。
資料生成
��根據使用者上傳的範例資料,利用語言模型生成更多的資料,隨後通過資料精煉與去重複等技術處理,最終產出一批高品質的資料供訓練使用。我們提供兩種資料精煉流程選擇——國網中心自行開發的資料精煉流程與工研院開發的資料精煉流程。
資料生成(工研院)專案執行位置: https://jenkins.genai.nchc.org.tw/job/01-data-automation/job/data-generation-ITRI/
資料生成(國網中心)專案執行位置: https://jenkins.genai.nchc.org.tw/job/01-data-automation/job/01-data-generation-NCHC/
資料品質評估
針對使用者提供的訓練資料進行品質評估,評估面向包含:錯別字、混淆度、多樣性與重複性。
資料品質評估專案執行位置: https://jenkins.genai.nchc.org.tw/job/01-data-automation/job/02-data-evaluation/
前置需求
GitLab 專案 (Repository)
使��用者將藉由 Gitlab Repository 提供資料,請按照以下步驟完成前置準備:
-
請先自行建立專案
-
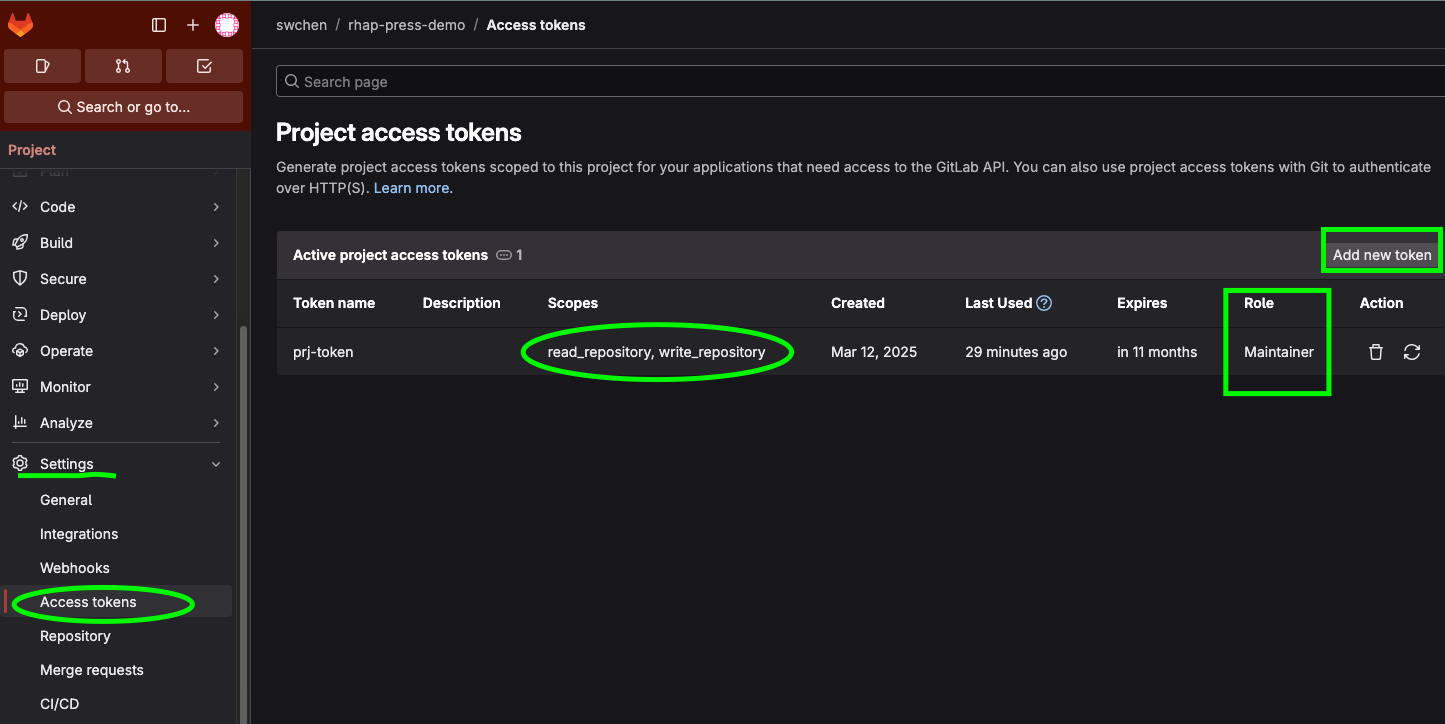
申請存取令牌(Access tokens)
(1) 申請方式:進入欲使用的專案 -> Settings -> Access tokens -> Add new token
(2) Scopes 選擇 read_repository, write_repository
(3) Role 選擇 Maintainer 或 Owner
(4) 存取令牌申請完成後,請務必存放在安全的地方,離開頁面後便無法再取得
-
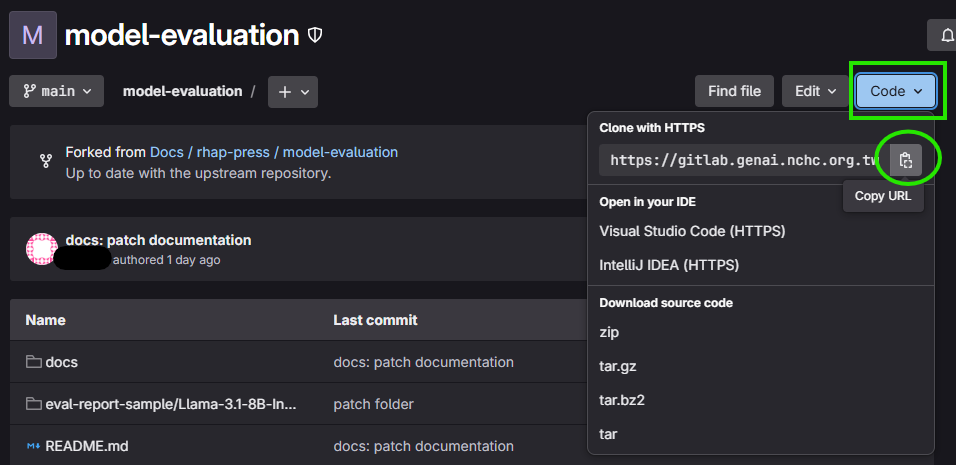
取得專案 URL
GIT_REPO_URL
-
將你的資料放置到專案並上傳
資料結構 請套用以下資料結構
.
└─── <version>
├── data
└── score操作引導
git clone <GIT_REPO_URL> # 你剛剛建立的專案
cd <git_repo_dir> # 進入專案目錄
mkdir <version> # 建立一個<version>資料夾
cd <version>
mkdir data # 建立 data 資料夾
cp <your_data_file> data/ # 將你自己的資料複製到 data 資料夾
mkdir score # 建立 score 資料夾。如果你沒有要進行資料品質評估,此步驟可省略
touch score/.gitkeep # 建立佔位檔案
git push origin main # 推回你的遠端專案 *注意* 如果你的資料大於100MB,請確認 LFS 追縱檔案(見下方說明)如果你的資料大於100MB,請使用 git LFS 安裝頁面
Ubuntu 安裝 GIT LFS# Install Git LFS
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get update
sudo apt-get install git-lfs
git lfs install
# 設定 LFS track,這裡假設要追蹤 .jsonl 檔案類型
git lfs track "*.jsonl"
git add .
git commit -m "設定 LFS 追蹤 .jsonl 檔案"
模型 API
資料生成
如果你選擇執行資料生成(工研院),那你僅會使用一個語言模型,用於資料生成 GEN_MODEL
如果你選擇執行資料生成(國網中心),那你會使用到兩個語言模型:1. 資料生成模型 GEN_MODEL 2. 資料精煉模型 DISTILLATION_MODEL
資料品質評估
資料品質評估僅會使用一個語言模型做錯別字偵測。僅限使用 國網中心API 取得模型服務
參數設定
基本設定
| 名稱 | 類型 | 說明 |
|---|---|---|
GIT_REPO_URL | 字串 | 『必填』請填入自行建立的 Git repository URL (例: https://gitlab.genai.nchc.org.tw/swchen/rhap-press-demo.git) |
GIT_REPO_TOKEN | 密碼 | Git repository 的存取令牌 (Access token); 請參考前置需求(需有 Maintainer/Owner 權限; 例: glpat-xxx) |
服務專屬設定
資料生成(工研院)
模型相關參數
| 名稱 | 類型 | 說明 |
|---|---|---|
GEN_MODEL | 字串 | 『必填』生成資料的模型,預設Llama-3.3-70B-Instruct。可選 Medusa 或其他公開模型(gpt-4o-mini, gpt-4o)Medusa 支援的模型列表 medusa-models.md |
GEN_API_URL | 字串 | 『必填』提供 GEN_MODEL 模型服務的 URL範例:Medusa: https://medusa-poc.genai.nchc.org.tw/v1 ; OpenAI: https://api.openai.com/v1 |
GEN_API_KEY | 密碼 | 『必填』使用 GEN_API_URL 的 API KEY |
流程參數
| 名稱 | 類型 | 說明 |
|---|---|---|
DATA_FILE | 字串 | 範例資料檔案路徑,如:<version>/data/train_set_1.jsonl |
SHEET_NAME | 字串 | 如果DATA_FILE是 EXCEL 檔案,請提供工作表名稱。預設 None |
TASK | 下拉選��單 | 公文/新聞稿/民眾陳情/模擬問答/其他,你提供的資料是屬於何項任務 |
TOPIC | 字串 | 如果 TASK 為其他,請填入該任務的主題 |
Q_COL | 字串 | DATA_FILE紀錄問題(使用者指令)的欄位名稱。預設 src_question |
A_COL | 字串 | DATA_FILE紀錄答案(回應)的欄位名稱。預設 src_answer |
DEFAULT_COUNT | 下拉選單 | 每一筆範例資料生成的資料筆數(1~5) |
SAMPLE | 正整數 | 預設 0,從最終產生的資料中取樣多少筆資料,0 為保留所有資料 |
進階設定
| 名稱 | 類型 | 說明 |
|---|---|---|
SYSTEM_MSG | 字串 | 系統提示詞。預設為不使用系統提示詞 |
DO_DEDUP | 下拉式選單 | True/False,預設 False 是否執行資料去重複 |
SIMILARITY_THRESHOLD | 數值 | ≤1 的數值,預設 0.99 相似度門檻值,相似度高於該值視為重複資料 |
DO_DISTILLATION | 下拉選單 | True/False,預設 False 是否執行資料精煉 |
DEBATE_TIMES | 下拉選單 | DO_DISTILLATION 資料精煉時的辯論次數(1~5) |
資料生成(國網中心)
模型相關參數
| 名稱 | 類型 | 說明 |
|---|---|---|
GEN_MODEL | 字串 | 『必填』生成資料的模型,預設Llama-3.3-70B-Instruct。可選 Medusa 或其他公開模型(gpt-4o-mini, gpt-4o)Medusa 支援的模型列表 medusa-models.md |
GEN_API_URL | 字串 | 『必填』提供 GEN_MODEL 模型服務的 URL範例:Medusa: https://medusa-poc.genai.nchc.org.tw/v1 ; OpenAI: https://api.openai.com/v1 |
GEN_API_KEY | 密碼 | 『必填』使用 GEN_API_URL 的 API KEY |
DISTILLATION_MODEL | 字串 | 資料精煉的模型,預設Llama-3.3-70B-Instruct。可選 Medusa 或其他公開模型(gpt-4o-mini, gpt-4o)Medusa 支援的模型列表 medusa-models.md |
DISTILLATION_API_URL | 字串 | 提供 DISTILLATION_MODEL 模型服務的 URL範例:Medusa: https://medusa-poc.genai.nchc.org.tw/v1 ; OpenAI: https://api.openai.com/v1 |
DISTILLATION_API_KEY | �密碼 | 使用 DISTILLATION_API_URL 的 API KEY |
流程參數
| 名稱 | 類型 | 說明 |
|---|---|---|
DATA_FILE | 字串 | 範例資料檔案路徑,如:<version>/data/train_set_1.jsonl |
SHEET_NAME | 字串 | 如果DATA_FILE是 EXCEL 檔案,請提供工作表名稱。預設 None |
TASK | 下拉選單 | 公文/新聞稿/民眾陳情/模擬問答/其他,你提供的資料是屬於何項任務 |
TOPIC | 字串 | 如果 TASK 為其他,請填入該任務的主題 |
Q_COL | 字串 | DATA_FILE紀錄問題(使用者指令)的欄位名稱。預設 src_question |
A_COL | 字串 | DATA_FILE紀錄答案(回應)的欄位名稱。預設 src_answer |
DEFAULT_COUNT | 下拉選單 | 每一筆範例資料生成的資料筆數(1~5) |
SAMPLE | 正整數 | 預設 0,從最終產生的資料中取樣多少筆資料,0 為保留所有資料 |
進階設定
| 名稱 | 類型 | 說明 |
|---|---|---|
SYSTEM_MSG | 字串 | 系統提示詞。預設為不使用系統提示詞 |
DO_DEDUP | 下拉式選單 | True/False,預�設 False 是否執行資料去重複 |
SIMILARITY_THRESHOLD | 數值 | ≤1 的數值,預設 0.99 相似度門檻值,相似度高於該值視為重複資料 |
DO_DISTILLATION | 下拉選單 | True/False,預設 False 是否執行資料精煉 |
資料品質評估
使用步驟

常見問題
Q: 資料格式要求?
A: 資料生成服務支援:.jsonl, .json, .xlsx;資料品質評估支援:.jsonl
Q: 資料品質評估的資料結構應該要是甚麼樣子?
A: 範例結構:
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": "交通部函知各縣市政府辦理交通建設工作一案,我要寫一份簽陳核示後,以便簽全案陳請首長室參酌。請提供簽及便簽主旨及說明,交通部來函如下:\n\n主旨:檢送交通建設工作計畫一份,請查照。\n說明:\n一、依據交通部來函辦理。\n二、檢送交通建設工作計畫一份。"}, {"role": "assistant", "content": "<think>\n首先,我們需要了解指令的內容,即交通部函知各縣市政府辦理交通建設工作一案。接下來,我們需要根據交通部來函的內容,撰寫一份簽陳核示的公文。簽陳核示的公文需要包括主旨、說明等部分。在主旨部分,我們需要簡明扼要地表達公文的內容。在說明部分,我們需要根據交通部來函的內容,列出相關的依據和內容。另外,我們還需要撰寫便簽說明,包括相關的背景、內容和處理方式。最後,我們需要根據相關的法規和政策,確保公文的內容正確、完整。\n</think>\n\n簽內容擬稿如下:\n主旨:有關交通建設工作計畫一案,簽請核示。\n說明:\n一、依據交通部本(O)年O月O日O字第O號函辦理。 \n二、來文內容如下:交通部為加強交通建設工作,特檢送交通建設工作計畫一份,請各縣市政府參酌辦理。\n三、旨揭更新版交通建設工作計畫陳送首長室保管使用。\n\n便簽說明如下:\n\n一、有關交通部製作之「交通建設工作計畫」,業經O年O月O日O號簽準在案,謹請鈞閱。\n二、另舊版交通建設工作計畫,敬請逕行銷毀。\n三、謹陳「交通建設工作計畫」暨原簽陳影本各1份。"}]}
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": "內政部檢送「都市更新條例」修正草案,請財政部於110年6月30日前提出審查意見"}, {"role": "assistant", "content": "<think>\n首先,我們需要了解指令的內容,即內政部檢送「都市更新條例」修正草案,請財政部提出審查意見。接下來,我們需要根據相關法規和作業要點進行思考。在這個案例中,財政部需要根據「財政部審查都市更新事業財務計畫作業要點」進行審查。因此,我們需要思考如何根據這些規定提出審查意見。最後,我們需要根據思考結果撰寫公文內容,包括主旨、說明等部分。\n</think>\n\n函:\n主旨:有關「都市更新條例」修正草案審查意見\n說明:\n一、復貴部○○○年○月○○日內授都市字第1100000000號函。\n二、依「財政部審查都市更新事業財務計畫作業要點」規定,財政部應審查都市更新事業之財務計畫,確保其財務可行性。\n三、查修正草案中有關都市更新事業財務計畫之規定,財政部認為應加強財務審查機制,避免都市更新事業財務風險。"}]}
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": "請各機關學校填報有關「能源節約」執行成果,請提供書函的主旨與說明"}, {"role": "assistant", "content": "<think>\n首先,我們需要了解指令的內容,即各機關學校需要填報有關「能源節約」執行成果的相關資料。根據指令,需要提供書函的主旨與說明。因此,我們需要根據經濟部的相關規定和檔案,撰寫書函的內容。書函的主旨應該明確指出填報的目的和截止日期,說明部分則需要提供相關的背景、填報專案和注意事項。根據經濟部的檔案和規定,能源節約是重要的工作,因此需要各機關學校積極參與和填報相關資料。\n</think>\n\n主旨:為協助經濟部統計有關「能源節約」執行成果,請於○○○年○○月○○日前依附件格式填報相關表格(如附件1、2),無執行成果者亦請回復,請查照。\n說明:\n一、依經濟部○○○年○月○○日經授能字第1130760452號函辦理。\n二、為推動能源節約,請各機關學校繼續規劃相關推動內容及作為,並依附件格式填報○○○年○月○日至○○○年○月○○日之推動成果,本次填報專案說明及注意事項詳如附件3。"}]}
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": "文化部來函申請文化藝術計畫經費,請擬1份回函給文化部,並提供回覆的書函主旨及說明。文化部來函主旨如下:\n○○○年度文化藝術計畫經費補助,核定編號○○○,請審核。"}, {"role": "assistant", "content": "<think>\n首先,我們需要了解文化部的來函內容,包括申請補助經費的目的和金額。接下來,我們需要根據相關法規和程式進行審核和核定。根據文化部的規定,文化藝術機構需要提交經費補助申請表,並提供詳細的經費明細。經過審核後,文化部將撥付補助款項至文化藝術基金專戶。因此,在回覆中,我們需要明確表示同意補助的金額和撥付方式。\n</think>\n\n回函主旨及說明如下:\n主旨:所送文化部申請○○○年度文化藝術計畫經費補助事,復如說明,請查照。\n說明: \n一、復文化部○年○月○日○號函。\n二、本案(計畫編號:○)所送經費補助申請表經審核,同意補助新臺幣○元;款項將由文化部直接撥付至文化藝術基金專戶。"}]}
Q: 已經創建空的目錄,但 git 無法追縱空目錄
A: 請在空白目錄裡建立一個佔位檔案 .gitkeep
Q: 資料評分指標怎麼解讀?
A: 資料品質評估執行完畢會計算出四項指標,各項分數代表含意請見下表:
| 欄位名稱 | 說明(分數皆越高越好) |
|---|---|
| Typo-Free Score | 檢測語句錯別字,錯別字越少分數越高 |
| Fluency Score | 代表語句的通暢性 |
| Diversity Score | 代表整個資料集的全局多樣性 |
| Distinct Score | 檢測資料集的局部重複性,重複越少分數越高 |